Introduction
In Kubernetes, a Horizontal Pod Autoscaler (HPA) automatically updates a workload resource (such as a Deployment or StatefulSet), with the aim of automatically scaling the workload to match demand.
Let’s deep dive in this post and understand how Kubernetes implements a Horizontal Pod Autoscaling.
What is Horizontal Scaling?
👉 Horizontal scaling in Kubernetes means deployment of more number of pods in order to complete the demand when the traffic increases for an application.
👉 This is different from vertical scaling, which for Kubernetes would mean assigning more resources (CPU/Memory) for the already running workload.
How does a HorizontalPodAutoscaler work?
👉 Let’s deep dive and understand how Kubernetes implements a Horizontal Pod Autoscaling.
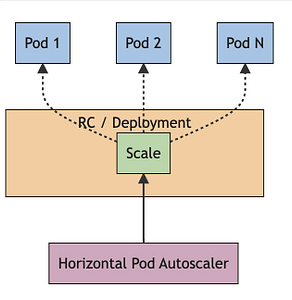
(Image Credit: Kubernetes official docs)
Control Loop
👉 Kubernetes implements horizontal pod autoscaling as a control loop (which is managed by the kube-controller-manager) that runs intermittently (it is not a continuous process).
👉 This control loop runs every 15 seconds (by default), however, this can be customized by the parameter “--horizontal-pod-autoscaler-sync-period“
👉 At every run, the controller manager fetches the resource utilization against the metrics specified in each HPA definition.
👉 For per-pod resource metrics (like CPU, Memory), the controller fetches the metrics from the resource metrics API for each Pod targeted by the HorizontalPodAutoscaler.
👉 Then, if a target utilization value is set, the controller calculates the utilization value as a percentage of the equivalent resource request on the containers in each Pod.
👉 If a target raw value is set, the raw metric values are used directly.
👉 The controller then takes the mean of the utilization or the raw value (depending on the type of target specified) across all targeted Pods, and produces a ratio used to scale the number of desired replicas.
Metrics Server and API
👉 A metrics server needs to be installed and configured in the cluster.
👉 It fetches resource metrics from the kubelets and exposes them in the Kubernetes API server through the Metrics API for use by the HPA and VPA.
👉 There can be 3 types of Metrics API:
🔹 metrics.k8s.io
🔹 custom.metrics.k8s.io
🔹 external.metrics.k8s.io
Algorithm details for HPA
👉 HPA controller works on on the ratio between current metric value and desired metric value:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]👉 For example, if the current metric value is 200m, and the desired value is 100m, the number of replicas will be doubled, since 200.0 / 100.0 == 2.0
💡One important thing to NOTE is HPA works only on resource requests, not limits.



